



La empresa de Alphabet, compañía matriz de Google, y el Laboratorio Europeo de Biología Molecular (EMBL) publicaron una importante base de datos que será abierta y pública. La importancia de este desarrollo en la investigación biológica y el desarrollo de fármacos.
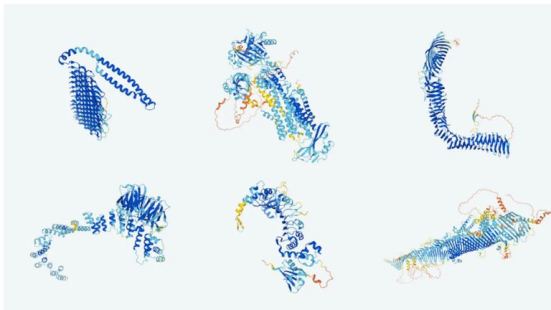
La empresa DeepMind -que fue adquirida en 2016 por Alphabet, empresa matriz de Google- y el Laboratorio Europeo de Biología Molecular (EMBL) emplearon el sistema de inteligencia artificial AlphaFold para publicar la base de datos más completa y precisa de las predicciones de las estructuras de las proteínas humanas.
La base de datos, abierta para la comunidad científica y que estará alojada en el Instituto Europeo de Bioinformática (EMBL-EBI), incluirá alrededor de 20.000 proteínas expresadas por el genoma humano.
Entre las primeras 350.000 estructuras publicadas en la base de datos, además del proteoma humano, están las proteínas de 20 organismos biológicamente significativos como E. coli, la mosca de la fruta, el ratón, el pez cebra, el parásito de la malaria y las bacterias de la tuberculosis.
Con ello, se amplía drásticamente el conocimiento acumulado sobre las estructuras de proteínas, más que duplicando el número de estructuras de proteínas humanas con predicciones de alta precisión disponibles para los investigadores, lo que permitirá acelerar el trabajo en gran variedad de campos, señaló el EMBL en una nota.
La revista Nature publicó hoy un estudio en el que se describe cómo se realizan estas predicciones y proporciona la imagen más completa de las proteínas que componen el proteoma humano (el conjunto de proteínas codificadas por el genoma humano), cuya comprensión es de gran importancia para la salud y la medicina.
El conjunto de datos resultante proporciona una predicción fiable de la posición estructural de casi el 60% de los aminoácidos del proteoma humano.
Los autores del estudio vieron que el algoritmo AlphaFold era capaz de predecir “con confianza” la posición estructural del 58% de los aminoácidos del proteoma humano.
De ellos, la posición de un subconjunto del 35,7% se predijo con un grado de confianza “muy alto”, lo que supone el doble del número cubierto por las estructuras experimentales, explicó la revista.
Las proteínas tienen una forma tridimensional única que las lleva a encajar unas en otras, pero determinarla supone un gran reto. El uso de la inteligencia artificial permitió crear la base de datos más completa de predicciones sobre cómo se pliegan estas moléculas.
La estructura de cada proteína -pieza fundamental de la vida-, que depende de los aminoácidos que la componen, define lo que hace y cómo lo hace. De ahí que poder determinarla aporta información valiosa para entender los procesos biológicos, con el objetivo de avanzar en diversos campos de investigar y para el desarrollo de fármacos a futuro.
Los investigadores consideran que la predicción de estructuras a gran escala y con precisión se convertirá “en una herramienta importante que permitirá abordar nuevas cuestiones científicas desde una perspectiva estructural”, y las predicciones de AlphaFold ayudarán a esclarecer aún más el papel de las proteínas.
“Creemos que esta es la contribución más significativa que ha hecho la inteligencia artificial al avance del conocimiento científico hasta la fecha, y es un gran ejemplo de los tipos de beneficios que la inteligencia artificial puede aportar a la sociedad”, según el fundador de DeepMind, Demis Hassabis.
El uso de la inteligencia artificial, con su capacidad de predecir computacionalmente la forma de una proteína a partir de su secuencia de aminoácidos, permite que no se tenga que determinar de forma experimental con el uso de técnicas laboriosas y a veces costosas.
AlphaFold fue entrenado con datos de recursos públicos creados por la comunidad científica, por lo que tiene sentido que sus predicciones sean públicas, defendió la directora general del EMBL, Edith Herad.
Esta herramienta, que para Herad es “una verdadera revolución para las ciencias de la vida, así como fue la genómica hace varias décadas”, está siendo ya usada por la Iniciativa de Medicamentos para Enfermedades Desatendidas.
Además un grupo de la Universidad de California en San Francisco ha utilizado las predicciones de ese algoritmo para estudiar la biología del SARS-CoV-2.